Motivation and Description
Whenever new LLMs come out, I find myself poking around with them to try to see how capable they are compared to previous generations. One category of questions I found myself asking a lot were questions about my favorite band, the Mountain Goats. In particular, I would ask LLMs to try to list out all of the songs in various Mountain Goats albums in order and see how they did. This benchmark is my attempt at automating this type of evaluation.
The benchmark is composed of two types of questions. First, the "list" questions, just give the model the name of a Mountain Goats album and asks it to output all of the song names for that album in order. I included all studio-released Mountain Goats albums. Second, there are short answer questions, which ask the model to answer, in free-form, some questions about the band. These questions range in difficulty from "Who is the lead singer and primary songwriter of The Mountain Goats?", which basically all models get right, up to things like "In the song Going to Georgia, a firearm is mentioned. According to the song, what year was that firearm manufactured?", which basically no models get right.
Technical Details
The benchmark itself is a fairly simple typescript file running on bun. I used OpenRouter for the backend, as it makes it really easy to add new models as they release. I do my best to run every new model to see how things are progressing. I wrote the benchmark in December of 2025, primarily using Opus 4.5 in Claude Code and have made small changes since then. The benchmark implementation itself took a couple hours, plus a couple more for me writing all the short answer questions. I wasn't too concerned with optimization for this, though did add some parallelization of API calls to make it run faster. Overall, though, this is meant to be an interesting little test more than a bulletproof production-ready codebase.
Results
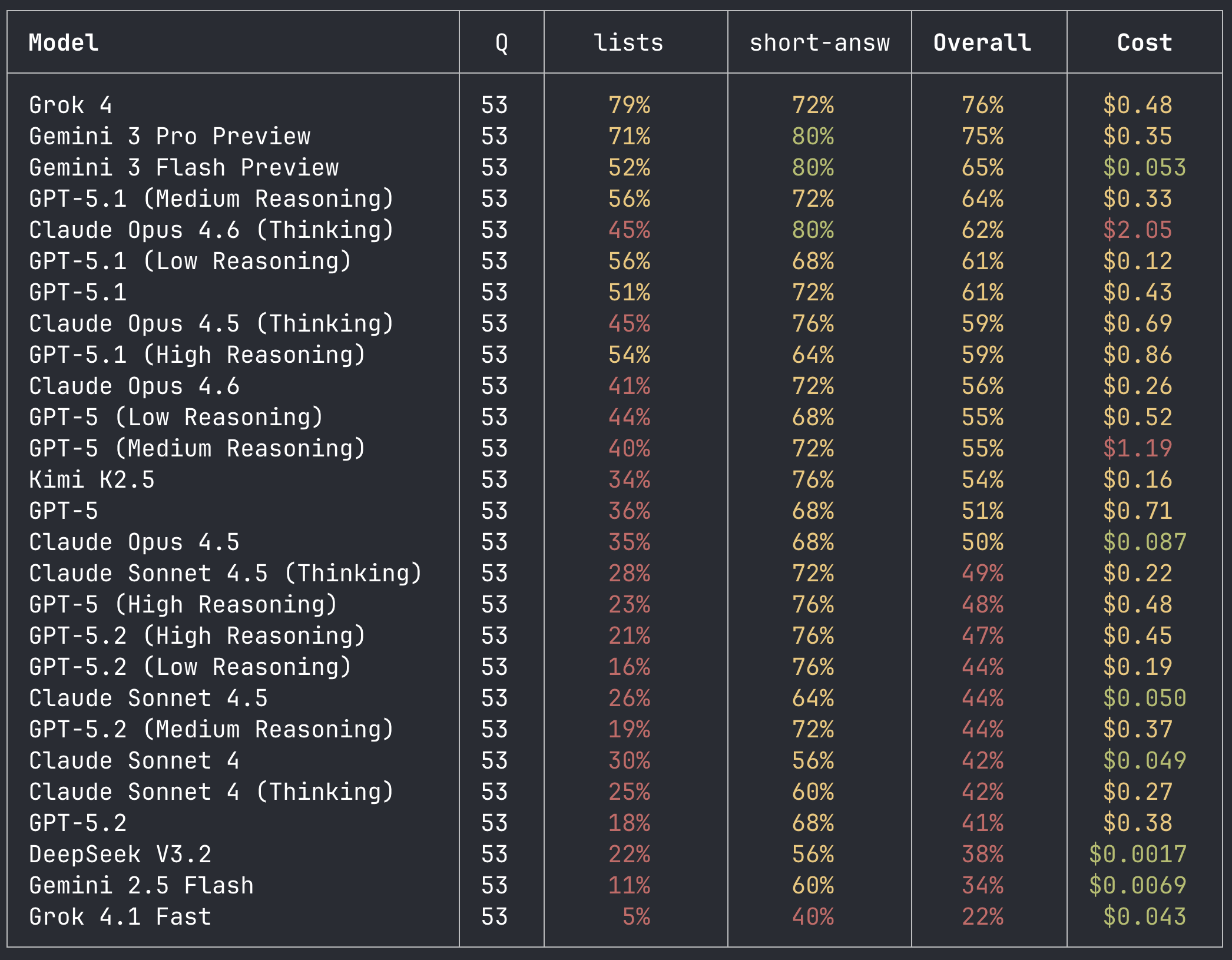
I would say that, overall, I found the results of the benchmark (pictured below) to be quite surprising. In particular, Grok 4 being the absolute top performer is not something I would have predicted beforehand. The Grok models really are quite strange. They aren't especially useful, in my opinion, compared to OpenAI and Anthropic models, but they do seem to have a lot of knowledge in them. Notable that Grok owns both ends of the benchmark, having both the best and worst performing model among those I tested. Another interesting result was the regression between GPT-5.1 and GPT-5.2, with a 20% drop in performance on medium reasoning effort also costing an additional 4 cents to run. Not sure exactly what's going on here; this could be some weak evidence in favor of the hypothesis that 5.2 was a different pre-train from 5 and 5.1.
All the other results are fairly normal. Gemini models are near the top of the leaderboard. Anthropic shows a clear progression of improvement over time, with each new model doing better than the last. Kimi K2.5 puts up a pretty good performance, particularly for an open weight model.
Ultimately, what I think this benchmark is measuring is "how much knowledge is encoded in the model", which is slightly different from, more broadly, how "smart" a model is (hence why Grok 4 can be at the top of the leaderboard but still one of the least deployed frontier models, and why 5.2 can know less about the Mountain Goats while being an extremely smart model). The Mountain Goats are a good candidate for measuring this type of knowledge because they are prominent enough that all the LLMs know about them but esoteric enough that there is plenty of headroom on the benchmark.